
이번 주부터 한국외대 DSC(Developer Student Club) 멤버들과 함께 머신러닝 스터디를 하면서 “머신 러닝 교과서“를 블로그에 정리해서 올릴 예정이다.
1장 컴퓨터는 데이터에서 배운다
머신러닝의 주요 개념과 종류를 배운다. 관련 용어 소개와 머신러닝 기술을 실제 문제 해결에 성공적으로 적용할 수 있는 초석을 다진다.
- 머신 러닝의 일반적 개념 이해하기
- 세 종류의 학습과 기본 용어 알아보기
- 성공적인 머신 러닝 시스템을 설계하는 필수 요소 알아보기
- 데이터 분석과 머신 러닝을 위한 파이썬을 설치하고 설정하기
1.1 데이터를 지식으로 바꾸는 지능적인 시스템 구축
현대 기술에는 정형 또는 비정형 데이터가 풍부하다. 20세기 후반에 이런 데이터에서 지식을 추출하여 예측하는 자기 학습(self-learning) 알고리즘과 관련된 인공지능(Artificial Intelligent, AI)의 하위 분야로 머신러닝이 출현하고 큰 역할을 하고 있다. 예) 이메일 스팸 필터, 편리한 텍스트, 음성 인식, 웹 검색 엔진, 체스 대결 프로그램 등
1.2 머신러닝의 세 가지 종류
머신 러닝의 세가지 종류
- 지도 학습(supervised learning)
- 레이블된 데이터
- 직접 피드백
- 출력 및 미래 예측
- 비지도 학습(unsupervised learning)
- 레이블 및 타깃 없음
- 피드백 없음
- 데이터에서 숨겨진 구조 찾기
- 강화 학습(reinforcement learning)
- 결정 과정
- 보상 시스템
- 연속된 행동에서 학습
1.2.1 지도 학습으로 미래 예측
- 지도 학습의 주요 목적: 레이블(label)
- 지도(supervised): 희망하는 출력 신호(레이블)가 있는 일련의 샘플 예) 스팸 메일 예측
- 분류(classification)
- 지도 학습의 하위 카테고리
- 클래스 레이블은 이산적(discrete)이고 순서가 없어 샘플이 속한 그룹으로 이해할 수 있다.
- 이진 분류(binary classification)
- 다중 분류(multiclass classification)
- 결정 경계(decesion boundary)
- 회귀(regression)
- 연속적인 출력 값 예측
- 예측 변수(predictor variable 또는 설명변수(explanatory variable), 입력(input))와 연속적인 반응 변수(response variable 또는 출력, 타깃)가 주어질 때 출력 값을 예측하는 두 변수 사이의 관계를 찾는 것.
- 선형 회귀(linear regression)
- 절편(intercept)
1.2.2 강화 학습으로 반응형 문제 해결
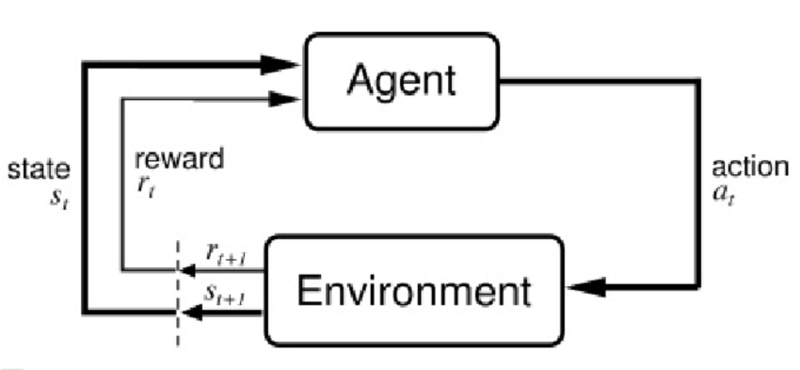
환경과 상호 작용하여 시스템(에이전트(agent)) 성능을 향상하는 것이 목적이다. 환경의 현재 상태 정보는 보상(reward) 신호를 포함하기 때문에 강화학습을 지도 학습과 관련된 분야로 생각할 수 있다. 강화 학습의 피드백은 정답(ground truth) 레이블이나 값이 아니다. 보상 함수로 얼마나 행동이 좋은지를 측정한 값이다. 에이전트는 환경과 상호 작용하여 보상이 최대화되는 일련의 행동을 강화 학습으로 학습한다. 탐험적인 시행착오(trial and error) 방식이나 신중하게 세운 계획을 사용한다.
예) 체스 게임(체스판의 상태(환경)에 따라 기물의 이동을 결정함)
이 책에서는 강화학습을 여기서 마무리한다.
1.2.3 비지도 학습으로 숨겨진 구조 발견
비지도 학습에서는 레이블되지 않거나 구조를 알 수 없는 데이터를 다룬다.
군집: 서브그룹 찾기
사전 정보 없이 쌓여 있는 그룹 정보를 의미 있는 서브그룹(subgroup) 또는 클러스터(cluster)로 조직하는 탐색적 데이터 분석 기법
차원 축소: 데이터 압축
차원 축소(dimensionality reduction)는 고차원 데이터를 다루어야 하는 경우는 흔하다. 비지도 차원 축소는 잡음(noise) 데이터를 제거하기 위해 특성 전처리 단계에서 종종 적용하는 방법이다. 잡음이 특정 알고리즘의 예측 성능을 감소시킬 수 있다. 더 작은 차원의 부분 공간(subspace)으로 데이터를 압축한다. 데이터 시각화(산점도(scatterplot) ,히스토그램(histogram))에도 유용하다.

비선형(nonlinear) 차원 축소를 통해 3D 스위스롤(swiss roll)을 압축한 모습
1.3 기본 용어와 표기법 소개
붓꽃(Iris)를 예로 들었다. (데이터셋 구성: Setosa, Versicolor, Virginica 세 종류 150개의 붓꽃 샘플) 각 붓꽃 샘플은 하나의 행(row), 센티미터 단위의 측정값은 열(column)에 저장되고, 데이터셋의 특성(feature)이라고도 한다.
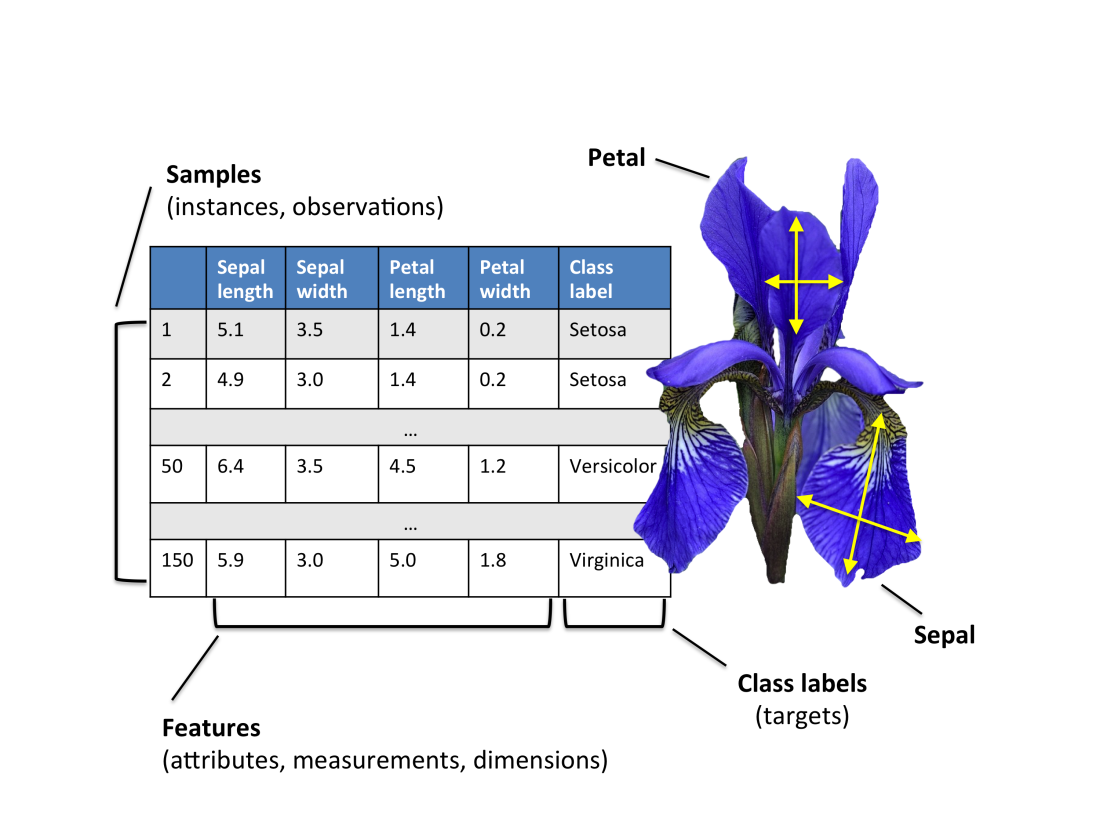
기초적인 선형대수학(linear algebra)을 사용해서 설명한다. 데이터는 행렬(matrix)과 벡터(vector) 표기로 나타낸다. 샘플은 특성 행렬 X에 있는 행으로 나타내고, 특성은 열을 따라 저장한다.
1.4 머신 러닝 시스템 구축 로드맵
머신 러닝의 기초 개념과 세 종류의 학습 방법을 설명한다. 학습 알고리즘과 함께 머신 러닝 시스템의 중요한 다른 부분을 다룬다. 아래 그림은 예측 모델링에 머신 러닝을 사용하는 전형적인 작업 흐름이다.
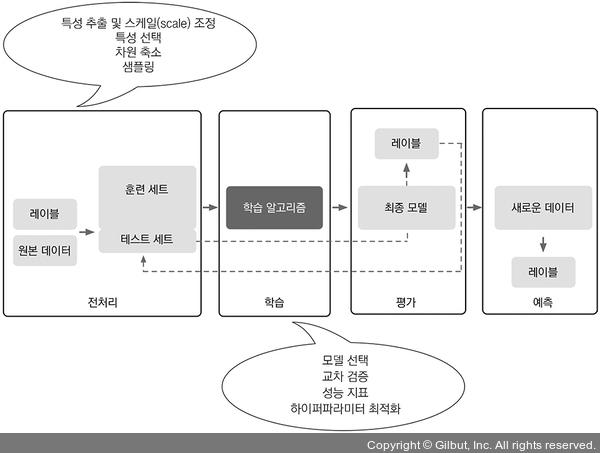
1.4.1 전처리: 데이터 형태 갖추기
원본 데이터의 형태와 모습으로 학습 알고리즘이 최적의 성능을 내기에 부적합하다. 그래서 데이터 전처리는 매우 중요한 작업이다.

많은 머신 러닝 알고리즘에서 최적의 성능을 내려면 선택된 특성이 같은 스케일을 가져야 한다. 특성을 [0,1] 범위로 변환하거나 평균이 0이고 단위 분산을 가진 표준 정규 분포(standard normal distribution)로 변환하는 경우가 많다.
차원 축소 기법을 사용하여 특성을 저차원 부분 공간으로 압축하기도 한다. 어떤 경우에는 차원 축소가 모델의 예측 성능을 높이기도 한다. 데이터셋에 관련 없는 특성(또는 잡음)이 매우 많을 경우, 즉 신호 대 잡음비(Signal-to-Noise Ratio, SNR)가 낮은 경우이다.
데이터셋을 훈련셋과 테스트 셋으로 나누어야 한다.
1.4.2 예측 모델 훈련과 선택
최소한 몇 가지 알고리즘을 비교해야 한다. 여러 모델을 비교하기 전에 먼저 성능을 측정할 지표를 결정해야 한다. 교차 검증 기법, 하이퍼파라미터(hyperparmeter) 최적화 기법 등을 활용할 수 있다.
1.4.3 모델을 평가하고 본 적 없는 샘플로 예측
훈련 세트에서 최적의 모델을 선택한 후에는 테스트 세트를 사용하여 이전에 본 적이 없는 데이터에서 얼마나 성능을 내는지 예측하여 일반화 오차를 예상한다.
1.5 머신 러닝을 위한 파이썬
- 파이썬은 데이터 과학 분야에서 가장 인기 있는 프로그래밍 언어이다.
- 포트란(Fortran)과 C 언어로 만든 저수준 모듈 위에 구축된 Numpy와 Scipy 같은 라이브러리가 있다. (다차원 배열에서 벡터화된 연산을 빠르게 수행할 수 있음.)
- Scikit-learn 라이브러리로 대부분 머신 러닝 프로그래밍 작업을 한다. (현재 가장 인기 있고 사용하기 쉬운 오픈 소스 머신러닝 라이브러리 중 하나다.)
1.5.1 파이썬과 PIP에서 패키지 설치
파이썬 공식 웹 사이트(https://www.python.org)에서 문서와 설치 파일을 내려받을 수 있다. 해당 책은 3.7.2 버전과 그 이상에 맞추어져 있다. 파이썬 3을 권장한다.
책에서 사용할 패키지는 pip 설치 프로그램으로 설치할 수 있다. 자세한 pip 설명은 온라인 문서(https://wiki.python.org/3/installing/index.html)를 참고하면 된다.
# 파이썬을 설치하고 난 후 터미널(Terminal)에서 pip 명령으로 필요한 파이썬 패키지를 설치할 수 있다.
pip install <패키지 이름>
# 설치할 패키지를 업데이트할 때는 --upgrade 옵션을 사용한다.
pip install --upgrade <패키지 이름>
1.5.2 아나콘다 파이썬 배포판과 패키지 관리자 사용
과학 컴퓨팅을 위해서는 아나콘다(Anaconda) 파이썬 배포판을 권장한다. 아나콘다는 상업적 목적을 포함하여 무료로 사용 가능하다. 데이터 과학, 수학, 공학용 파이썬 필수 패키지들을 모두 포함하고 있으며 주요 운영 체제를 모두 지원한다. 아나콘다 설치 파일은 https://www.anaconda.com/download/ 에서 내려받을 수 있다.
# 아나콘다를 설치한 후 다음 명령으로 필요한 파이썬 패키지를 설치할 수 있다.
conda install <패키지 이름>
# 설치한 패키지를 업데이트할 때는 다음 명령을 사용한다.
conda update <패키지 이름>
1.5.3 과학 컴퓨팅, 데이터 과학, 머신 러닝을 위한 패키지
사용하는 패키지와 버전
- Numpy 1.16.1
- Scipy 1.2.1
- Scikit-learn 0.20.2
- Matplotlib 3.0.2
- Pandas 0.24.1
- Tensorflow 2.0.0
1.6 요약
기본적인 개념과 로드맵을 살펴 보았고, 파이썬 환경과 필수 패키지를 설치하고 업데이트해서 머신 러닝 작업할 준비를 마쳤다.