
한국외대 DSC(Developer Student Club) 멤버들과 함께 머신러닝 스터디를 진행하면서 “머신 러닝 교과서“를 블로그에 정리한 내용입니다.
누락된 데이터 다루기
-
누락된 데이터 예시: null, NaN(Not a Number)
-
Pandas DataFrame으로 데이터를 읽어온다. 누락된 값은 isnull로 확인 가능하다. 누락되면 True, 아니면 False 반환
df.isnull().sum() ''' A 0 B 0 C 1 D 1 dtype: int64 '''
누락된 데이터 다루는 방법
- 누락된 값이 있는 샘플이나 특성 제외 -> 방법 제시
- Pandas DataFrame 변수의 함수로 쉽게 제거 가능
- 단점: 너무 많은 데이터를 제거하면 분석이 불가능할 수 있다.
# 누락된 값이 있는 행을 삭제합니다.
df.dropna(axis=0)
- 보간(Interpolation) 기법으로 누락된 값 대체
- 평균, 중간값 활용
# 누락된 값을 열의 평균으로 대체합니다.
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
imr = imr.fit(df.values)
imputed_data = imr.transform(df.values)
imputed_data
사이킷런 추정 API
fit 메서드로 훈련 데이터의 모델 파라미터를 학습 후 transform 메서드로 학습한 파라미터로 데이터를 변환합니다.
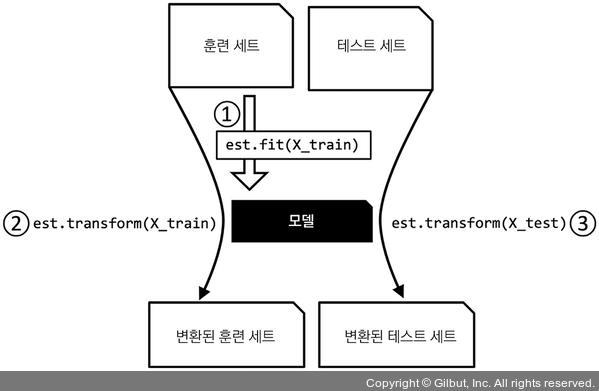
범주형 데이터 다루기
실제 데이터는 범주형일 경우가 많다.
순서가 있는 데이터와 순서가 없는 데이터
- 순서 잇는 데이터의 경우 순서 특성 맵핑
- Enum 활용
- Dictionary 자료형 활용해서 각 변수를 정수에 맵핑한다.
- 순서 없는 데이터
- Labelencoding
- 정수의 크기가 학습에 영향 미칠 수 있음.
- one-hot encoding
- 특성 데이터를 희소 행렬로 변환한다
- Labelencoding
데이터셋을 훈련셋과 테스트셋으로 나누기
- 사이킷런의 model_selection의 train_test_split 함수로 쉽게 다룰 수 있다.
특성 스케일 조정하기
- 정규화
- 최소-최대 스케일 변환 (min-max scaling)
- 표준화
- 표준화 공식 제공
유용한 특성 선택
과대 적합(overfitting)의 문제가 생길 수 있다. 과소 적합의 문제도 있는데 과소적합은 데이터가 모자랄 뿐 아니라 전반적인 개발의 문제이기 때문에 근거를 특정하기 힘들어서 다루지 않은 것으로 보인다.
과대 적합의 문제를 해결하는 방법은 아래와 같다.
- 데이터 차원의 축소
- L2 규제
- L1 규제
순차 선택 알고리즘
- 차원 축소
- 특성 선택
- 순차 특성 선택: 순차 후진 선택
- 특성 추출
- 특성 선택
랜덤 포레스트의 특성 중요도 사용
랜덤 포레스트를 사용하면 앙상블에 참여한 모든 결정 트리에서 계산한 평균적인 불순도 감소로 특성 중요도를 측정할 수 있습니다.